⚡ Binary & Hex
Computers store everything as binary — sequences of 1s and 0s. Each digit is called a bit. Just like decimal uses powers of 10 (ones, tens, hundreds...), binary uses powers of 2. In an 8-bit byte, the positions from right to left represent: 1, 2, 4, 8, 16, 32, 64, 128.
To read a binary number, add up the powers of 2 where there's a 1. For example, 00101010 = 32 + 8 + 2 = 42. Each bit doubles the maximum value: 8 bits can represent 0–255 (2⁸ = 256 values).
Hexadecimal (hex) is base-16, using digits 0–9 and letters A–F (for 10–15). Each hex digit represents exactly 4 bits, making it a compact way to write binary. A byte (8 bits) is always 2 hex digits: 2A in hex = 0010 1010 in binary = 42 in decimal. Programmers prefix hex with 0x, so you'll see 0x2A or 0xFF.
Cryptographic algorithms operate directly on bits — shuffling, mixing, and transforming them through operations like XOR, shifts, and rotations. Understanding binary is essential because these operations don't work on "numbers" in the mathematical sense; they work on bit patterns.
& Bitwise Operators
Bitwise operators are functions that operate on individual bits within a number. Unlike arithmetic operators that treat numbers as mathematical values, bitwise operators treat numbers as sequences of independent bits — each position processed separately.
AND outputs 1 only when both input bits are 1. It's commonly used for masking — extracting specific bits from a value. OR outputs 1 when either input bit is 1, useful for combining flags or setting specific bits. XOR (exclusive or) outputs 1 when the input bits differ — this is cryptography's favorite operator because it's perfectly reversible (A XOR B XOR B = A) and balanced (knowing the output tells you nothing about either input individually).
NOT inverts every bit, turning 1s to 0s and vice versa. In two's complement, NOT of a number equals -(x+1) — so NOT of 0 is -1, and NOT of 5 is -6.
In cryptography, these operators are categorized by their linearity. XOR is linear: if you know that A XOR B = C, and you change one bit in A, exactly one bit changes in C. This predictability makes XOR great for diffusion — spreading the influence of each input bit across the output. But predictability is also a weakness: an attacker can set up equations and solve them.
AND and OR are non-linear: the relationship between input and output changes depending on the other input. For AND, if one input is 0, the output is always 0 regardless of the other bit — information is destroyed. This unpredictability creates confusion, breaking the algebraic patterns an attacker might exploit. Secure algorithms need both: XOR to spread influence evenly, AND/OR to make the math unsolvable.
&|^~↻ Shifts & Rotations
Shifts slide all bits in a number left or right by a specified number of positions. Left shifts are equivalent to multiplying by powers of 2 — each position doubles the value. Right shifts divide by powers of 2. Bits that "fall off" the edge are discarded; new positions are filled with zeros (or with the sign bit for signed right shifts).
Rotations are shifts where nothing is lost — bits that fall off one end wrap around to the other. A right rotation by 7 positions moves each bit 7 places right, with the 7 rightmost bits appearing on the left. Rotations are crucial in cryptography because they preserve all information while changing its position, providing "diffusion" — spreading the influence of each input bit across the output.
Most programming languages don't have built-in rotation operators, so crypto code implements them manually by combining a right shift (moving bits right, filling left with zeros) with a left shift of the "lost" bits, then ORing them together. You'll see this pattern throughout SHA-256.
± Two's Complement
How do computers represent negative numbers? The naive approach would be to reserve one bit as a "sign bit" — 0 for positive, 1 for negative. But this creates problems: you'd have both +0 and -0, and addition would require special logic to handle signs.
Two's complement is a more elegant solution that's been universal since the 1960s. The rule is simple: to negate a number, flip all the bits and add 1. This single rule produces a number system where:
- There's only one zero (no +0/-0 confusion)
- Addition works identically for signed and unsigned numbers
- The hardware doesn't need to know which you're using
- Subtraction is just addition of the negated value
Let's see why this works. Take the 8-bit number +1: 00000001. To negate it, flip all bits: 11111110. Then add 1: 11111111. That's -1 in two's complement.
Now try adding them: 00000001 + 11111111 = 100000000. That's 9 bits — but we only have 8, so the top bit overflows and is discarded, leaving 00000000. We get zero, exactly as expected from 1 + (-1). The math just works, with no special cases.
The sign bit is the highest bit. If it's 1, the number is negative. For 8-bit: values 0-127 are positive, 128-255 represent -128 to -1. For 32-bit: the cutoff is at 2³¹ (about 2.1 billion). This is why 0xFFFFFFFF (all 32 bits on) equals -1 when interpreted as signed, not 4 billion.
Programming languages each handle this differently. Cryptographic algorithms are specified mathematically — "add these 32-bit unsigned integers" — but languages have their own ideas about how numbers work. Some languages, like JavaScript, have quirks where bitwise operations might treat numbers as signed, requiring special idioms to force an unsigned interpretation. Other languages, like Python, have arbitrary precision integers that never overflow, necessitating explicit masking to simulate fixed-width behavior. Languages like Go and Rust offer explicit sized types (e.g., uint32, i64) that more closely align with cryptographic specifications.
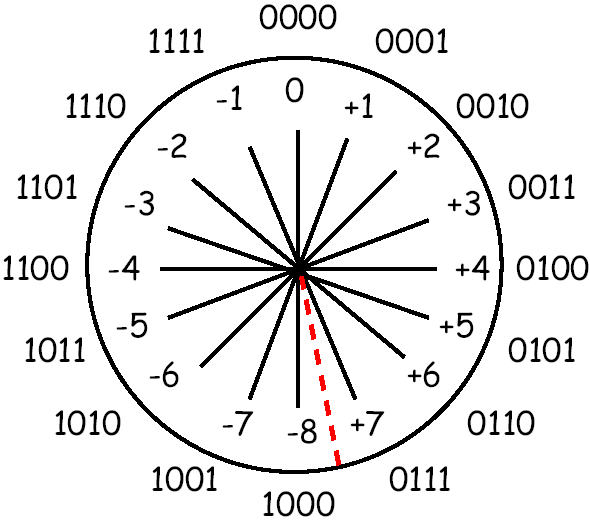
4-bit two's complement shown as a clock. Adding 1 moves clockwise; subtracting moves counter-clockwise. The red line marks where positive (+7) wraps to negative (-8).
# Hash Functions
A hash function takes an input of any size — a single character, a novel, an entire database — and produces a fixed-size output (256 bits for SHA-256, regardless of input size). This output is often called a "digest" or "fingerprint" because it uniquely identifies the input, much like a human fingerprint identifies a person.
Hash functions are one-way: given the output, there's no mathematical formula to recover the input. This isn't encryption (which is reversible by design) — it's closer to scrambling an egg. The only way to "reverse" a hash is to guess inputs until you find one that produces the target output (a brute-force attack). For SHA-256, this would take longer than the age of the universe.
The avalanche effect ensures that changing even a single bit of input changes approximately 50% of the output bits, in an unpredictable pattern. This makes it impossible to work backwards: similar inputs don't produce similar outputs, so you can't "get warmer" when guessing.
Hashes are everywhere: storing passwords (you store the hash, not the password), verifying file integrity (download matches expected hash?), digital signatures (sign the hash, not the whole document), blockchain (each block contains the hash of the previous block), and content-addressable storage (the hash IS the address).
Performance: Hash functions process data in fixed-size blocks (512 bits for SHA-256). The time to hash grows linearly with input size — hashing 1MB takes roughly 1000× longer than hashing 1KB. But "longer" is relative: modern CPUs with dedicated SHA instructions can hash gigabytes per second. The widget below demonstrates this — try typing increasingly long strings and notice the hash updates instantly.
⚙ SHA-256 Internals
SHA-256 might seem like magic — bytes go in, a completely unpredictable 256-bit number comes out. But it's actually a deterministic algorithm built entirely from the operations you've already learned: shifts, rotations, XOR, AND, and NOT. Here we'll implement it from scratch.
The algorithm processes data in 512-bit blocks. Each block goes through 64 rounds of mixing, where the current hash state is combined with the message data using carefully designed functions. The magic comes from two sources: confusion (non-linear operations like AND and NOT that make the relationship between input and output complex) and diffusion (rotations and XOR that spread each input bit's influence across all output bits).
The "magic numbers" in SHA-256 — the initial hash values and round constants — aren't arbitrary. They're derived from the square roots and cube roots of the first prime numbers, computed to 32 binary digits. This is called a "nothing up my sleeve" design: because anyone can verify these values come from primes, there's no suspicion of hidden backdoors. If the NSA had just picked random-looking hex values, you'd have to trust them.
>>> vs >>: >>> is unsigned right shift (fills with 0s). >> preserves the sign bit. Crypto needs unsigned.
Why 32-n? To rotate right by n bits: shift right n (bits fall off right), OR with shift left 32-n (puts those bits on the left). It's a circular shift on 32-bit integers.
>>> is unsigned right shift (fills with 0s). >> would preserve the sign bit — wrong for raw bits. << is left shift. Why 32-n? In a 32-bit rotate, bits that "fall off" the right must wrap to the left. x>>>n keeps the high bits; x<<(32-n) moves the low n bits to the top. OR combines them.
Without the length, "abc" and "abc\0\0\0..." would hash the same after padding. The 64-bit length also prevents length extension attacks — you can't append data without knowing the original length.
Why primes? Primes have no hidden structure — they can't be factored, so there's no "trick" to exploit. Why roots? √ and ∛ produce irrational numbers whose digits look random but are reproducible. Anyone can verify H0 = frac(√2)×2³² = 0x6a09e667. If the NSA had just picked hex values, you'd have to trust them.
Using different operations (square vs cube root) ensures H and K are mathematically independent. If both used √, there might be some algebraic relationship an attacker could exploit. The primes are also different: H uses primes 2-19, K uses primes 2-311.
The message schedule mixes earlier words into later rounds. σ0/σ1 use different rotation amounts to ensure each input bit affects many output bits. This creates the avalanche effect.
Ch: "if x then y else z" — non-linear selection. Maj: "majority vote" — also non-linear. Combined with rotations, these resist linear and differential cryptanalysis.
Cryptanalysts found attacks on reduced-round SHA-256 (up to 46 rounds). 64 provides a safety margin. Each round mixes bits further — after 64, every output bit depends on every input bit.
import hashlib
import math
message = b"abc"
print(f"Message: {message.decode()}\n")
# === DERIVE H FROM √PRIMES ===
# Same formula the JavaScript version uses
primes = [2, 3, 5, 7, 11, 13, 17, 19]
print("=== H constants from √primes ===")
for i, p in enumerate(primes):
sqrt = math.sqrt(p)
frac = sqrt - int(sqrt)
h = int(frac * 0x100000000)
print(f"H{i} = frac(√{p}) × 2³² = 0x{h:08x}")
# === K FROM ∛PRIMES (first 4) ===
print("\n=== K constants from ∛primes ===")
for i, p in enumerate([2, 3, 5, 7]):
cbrt = p ** (1/3)
frac = cbrt - int(cbrt)
k = int(frac * 0x100000000)
print(f"K{i} = frac(∛{p}) × 2³² = 0x{k:08x}")
# === USE STANDARD LIBRARY ===
# Python's hashlib uses the same algorithm internally
result = hashlib.sha256(message).hexdigest()
print(f"\nSHA-256 (hashlib): {result}")
# Expected for "abc":
# ba7816bf8f01cfea414140de5dae2223b00361a396177a9cb410ff61f20015ad
print(f"Expected: ba7816bf8f01cfea414140de5dae2223b00361a396177a9cb410ff61f20015ad")
print(f"Match: {'✓' if result == 'ba7816bf8f01cfea414140de5dae2223b00361a396177a9cb410ff61f20015ad' else '✗'}")
package main
import (
"crypto/sha256"
"fmt"
"math"
)
func main() {
message := []byte("abc")
fmt.Printf("Message: %s\n\n", message)
// === DERIVE H FROM √PRIMES ===
primes := []int{2, 3, 5, 7, 11, 13, 17, 19}
fmt.Println("=== H constants from √primes ===")
for i, p := range primes {
sqrt := math.Sqrt(float64(p))
frac := sqrt - math.Floor(sqrt)
h := uint32(frac * 0x100000000)
fmt.Printf("H%d = frac(√%d) × 2³² = 0x%08x\n", i, p, h)
}
// === K FROM ∛PRIMES (first 4) ===
fmt.Println("\n=== K constants from ∛primes ===")
for i, p := range []int{2, 3, 5, 7} {
cbrt := math.Cbrt(float64(p))
frac := cbrt - math.Floor(cbrt)
k := uint32(frac * 0x100000000)
fmt.Printf("K%d = frac(∛%d) × 2³² = 0x%08x\n", i, p, k)
}
// === USE STANDARD LIBRARY ===
hash := sha256.Sum256(message)
fmt.Printf("\nSHA-256 (crypto/sha256): %x\n", hash)
expected := "ba7816bf8f01cfea414140de5dae2223b00361a396177a9cb410ff61f20015ad"
fmt.Printf("Expected: %s\n", expected)
fmt.Printf("Match: %s\n", map[bool]string{true: "✓", false: "✗"}[fmt.Sprintf("%x", hash) == expected])
}
// Using sha2 crate: sha2 = "0.10"
use sha2::{Sha256, Digest};
fn main() {
let message = b"abc";
println!("Message: {}\n", String::from_utf8_lossy(message));
// === DERIVE H FROM √PRIMES ===
let primes = [2u32, 3, 5, 7, 11, 13, 17, 19];
println!("=== H constants from √primes ===");
for (i, &p) in primes.iter().enumerate() {
let sqrt = (p as f64).sqrt();
let frac = sqrt - sqrt.floor();
let h = (frac * 0x100000000_f64) as u32;
println!("H{} = frac(√{}) × 2³² = 0x{:08x}", i, p, h);
}
// === K FROM ∛PRIMES (first 4) ===
println!("\n=== K constants from ∛primes ===");
for (i, &p) in [2u32, 3, 5, 7].iter().enumerate() {
let cbrt = (p as f64).cbrt();
let frac = cbrt - cbrt.floor();
let k = (frac * 0x100000000_f64) as u32;
println!("K{} = frac(∛{}) × 2³² = 0x{:08x}", i, p, k);
}
// === USE STANDARD LIBRARY ===
let mut hasher = Sha256::new();
hasher.update(message);
let result = hasher.finalize();
println!("\nSHA-256 (sha2 crate): {:x}", result);
let expected = "ba7816bf8f01cfea414140de5dae2223b00361a396177a9cb410ff61f20015ad";
println!("Expected: {}", expected);
let result_hex = format!("{:x}", result);
println!("Match: {}", if result_hex == expected { "✓" } else { "✗" });
}
🌊 Avalanche Effect
The avalanche effect is what makes hash functions useful for security. It means that changing even a single bit of the input changes approximately half of the output bits, in a way that appears completely random. There's no pattern — changing bit 0 doesn't predictably affect output bit 0.
This property is crucial because it prevents "getting warmer." If similar inputs produced similar outputs, an attacker could start with a guess, compare the hash to the target, and iteratively adjust — like playing "hot and cold." The avalanche effect ensures that every wrong guess is equally wrong; there are no near-misses that hint at the correct answer.
SHA-256 achieves near-perfect avalanche: changing one input bit flips, on average, exactly 128 of the 256 output bits (50%), with each bit having an independent 50% chance of flipping. This is the theoretical ideal. In the code below, we'll flip a single bit and count exactly how many output bits change.
Without avalanche, attackers could guess parts of the input by analyzing the hash. With avalanche, every bit of input affects every bit of output — no partial information leaks.
Formally, SAC requires that flipping any single input bit has a 50% probability of flipping each output bit. SHA-256 satisfies this beautifully.
import hashlib
msg1 = "Hello"
msg2 = "hello" # Only one bit different!
hash1 = hashlib.sha256(msg1.encode()).digest()
hash2 = hashlib.sha256(msg2.encode()).digest()
# Convert to binary strings
def to_binary(data):
return ''.join(format(b, '08b') for b in data)
bits1 = to_binary(hash1)
bits2 = to_binary(hash2)
print(f"Message 1: {msg1}")
print(f"Message 2: {msg2}")
print("(Only 'H' → 'h' changed — that's 1 bit flip!)\n")
# Count differing bits
diff_count = sum(1 for a, b in zip(bits1, bits2) if a != b)
print("--- STATISTICS ---")
print(f"Bits changed: {diff_count} / {len(bits1)}")
print(f"Percentage: {diff_count/len(bits1)*100:.1f}%")
print(f"Expected ~50%: {'✓' if 115 <= diff_count <= 141 else 'unusual'}")
package main
import (
"crypto/sha256"
"fmt"
)
func main() {
msg1 := "Hello"
msg2 := "hello" // Only one bit different!
hash1 := sha256.Sum256([]byte(msg1))
hash2 := sha256.Sum256([]byte(msg2))
// Count differing bits using XOR
diffCount := 0
for i := 0; i < 32; i++ {
xor := hash1[i] ^ hash2[i]
for xor != 0 {
diffCount += int(xor & 1)
xor >>= 1
}
}
fmt.Printf("Message 1: %s\nMessage 2: %s\n\n", msg1, msg2)
fmt.Println("--- STATISTICS ---")
fmt.Printf("Bits changed: %d / 256\n", diffCount)
fmt.Printf("Percentage: %.1f%%\n", float64(diffCount)/256*100)
}
use sha2::{Sha256, Digest};
fn main() {
let msg1 = "Hello";
let msg2 = "hello"; // Only one bit different!
let hash1: [u8; 32] = Sha256::digest(msg1.as_bytes()).into();
let hash2: [u8; 32] = Sha256::digest(msg2.as_bytes()).into();
// Count differing bits using XOR and popcount
let diff_count: u32 = hash1.iter()
.zip(hash2.iter())
.map(|(a, b)| (a ^ b).count_ones())
.sum();
println!("Message 1: {}\nMessage 2: {}\n", msg1, msg2);
println!("--- STATISTICS ---");
println!("Bits changed: {} / 256", diff_count);
println!("Percentage: {:.1}%", diff_count as f64 / 256.0 * 100.0);
}
🎲 Collision Math
A collision occurs when two different inputs produce the same hash output. Hash functions map an infinite input space to a finite output space (2²⁵⁶ possible outputs for SHA-256), so collisions must exist mathematically. The security question is: can you find one?
The birthday paradox shows that collisions happen sooner than intuition suggests. In a room of just 23 people, there's a 50% chance two share a birthday — even though there are 365 possible days. The math scales: for SHA-256's 2²⁵⁶ possible outputs, you'd need about 2¹²⁸ hashes for a 50% collision chance.
Is 2¹²⁸ a lot? It's approximately 340 undecillion — more than the number of atoms in the observable universe. If you computed 10 billion SHA-256 hashes per second, it would take about 10¹⁹ years (a billion billion years) to reach 50% collision probability. For comparison, the universe is only 1.4 × 10¹⁰ years old.
Practical takeaway: For SHA-256, collisions are not a concern. You can safely use SHA-256 hashes as unique file identifiers, database keys, or content addresses. MD5 and SHA-1, however, have been "broken" — researchers have found practical collision attacks, which is why they're deprecated for security purposes.
In a room of 23 people, there's a 50% chance two share a birthday. Why? With n people, there are n(n-1)/2 pairs to check. For hashes: you need √(2^256) ≈ 2^128 hashes for 50% collision chance.
Bitcoin has computed ~2^93 SHA-256 hashes total (all mining ever). Still 2^35 times fewer than needed for collision. Even MD5 (broken) hasn't had a random collision found — only engineered ones.
import math
print("=== The Birthday Paradox ===\n")
# Classic birthday problem
def birthday_prob(people, days=365):
prob = 1
for i in range(people):
prob *= (days - i) / days
return 1 - prob
print("Probability of shared birthday:")
print(f" 23 people: {birthday_prob(23) * 100:.1f}%")
print(f" 50 people: {birthday_prob(50) * 100:.1f}%")
print(f" 70 people: {birthday_prob(70) * 100:.1f}%\n")
print("=== Hash Collision Probability ===")
print("For 50% collision chance, need √(output space) hashes\n")
hashes = [
("MD5", 128, True),
("SHA-1", 160, True),
("SHA-256", 256, False),
("SHA-512", 512, False),
]
print("Hash Output 50% collision at Status")
print("─" * 52)
for name, bits, broken in hashes:
exp = bits // 2
status = "⚠️ Broken" if broken else "✓ Secure"
print(f"{name:9} {bits} bits 2^{exp} hashes {status}")
print("\n=== Developer Takeaway ===")
print("• SHA-256 collisions: NOT a practical concern")
print("• MD5/SHA-1: avoid (theoretical breaks exist)")
package main
import "fmt"
func birthdayProb(people, days int) float64 {
prob := 1.0
for i := 0; i < people; i++ {
prob *= float64(days-i) / float64(days)
}
return 1 - prob
}
func main() {
fmt.Println("=== The Birthday Paradox ===\n")
fmt.Printf("23 people: %.1f%%\n", birthdayProb(23, 365)*100)
fmt.Printf("50 people: %.1f%%\n\n", birthdayProb(50, 365)*100)
fmt.Println("=== Hash Collision at 50% ===")
fmt.Println("MD5 (128 bits): 2^64 hashes ⚠️ Broken")
fmt.Println("SHA-1 (160 bits): 2^80 hashes ⚠️ Broken")
fmt.Println("SHA-256 (256 bits): 2^128 hashes ✓ Secure")
fmt.Println("SHA-512 (512 bits): 2^256 hashes ✓ Secure")
fmt.Println("\n=== Takeaway ===")
fmt.Println("SHA-256 collisions: NOT a practical concern")
}
fn birthday_prob(people: u32, days: u32) -> f64 {
let mut prob = 1.0;
for i in 0..people {
prob *= (days - i) as f64 / days as f64;
}
1.0 - prob
}
fn main() {
println!("=== The Birthday Paradox ===\n");
println!("23 people: {:.1}%", birthday_prob(23, 365) * 100.0);
println!("50 people: {:.1}%\n", birthday_prob(50, 365) * 100.0);
println!("=== Hash Collision at 50% ===");
println!("MD5 (128 bits): 2^64 hashes ⚠️ Broken");
println!("SHA-1 (160 bits): 2^80 hashes ⚠️ Broken");
println!("SHA-256 (256 bits): 2^128 hashes ✓ Secure");
println!("SHA-512 (512 bits): 2^256 hashes ✓ Secure");
println!("\n=== Takeaway ===");
println!("SHA-256 collisions: NOT a practical concern");
}
⟷ Symmetric Encryption
Symmetric encryption is the workhorse of cryptography. It uses a single secret key for both encryption and decryption — like a physical lock where the same key opens and closes it. If you and I share a secret key, I can encrypt a message that only you can read, and vice versa.
AES (Advanced Encryption Standard) is the symmetric cipher used by almost everything: your browser's HTTPS connection, your phone's disk encryption, your bank's transaction systems, government classified communications. It was selected by NIST in 2001 after a 5-year international competition, and has withstood decades of cryptanalysis. Intel CPUs have dedicated AES-NI instructions because it's that important.
GCM (Galois/Counter Mode) is how AES is typically used. It provides two guarantees: confidentiality (attackers can't read the encrypted data) and authenticity (attackers can't modify the encrypted data without detection). This "authenticated encryption" is critical — encryption alone doesn't prevent tampering, and modified ciphertext can cause all sorts of problems.
The limitation of symmetric encryption is key distribution: how do you and I agree on a shared secret key without an attacker intercepting it? This is the problem that asymmetric encryption solves.
The IV (Initialization Vector) ensures encrypting the same message twice produces different ciphertext. Must be unique per encryption, but doesn't need to be secret.
Selected by NIST in 2001 after a 5-year competition. Created by Belgian cryptographers Joan Daemen and Vincent Rijmen (algorithm name "Rijndael" = their names combined). Intel CPUs have dedicated AES-NI instructions.
Galois/Counter Mode provides both confidentiality AND integrity. If anyone tampers with the ciphertext, decryption will fail. Always use authenticated encryption!
A 128-bit key has 2¹²⁸ possibilities — more than atoms in the observable universe. 256-bit is for post-quantum security and government paranoia.
🧱 Block Cipher Modes
AES is a block cipher — it encrypts exactly 128 bits (16 bytes) at a time. But real messages are rarely exactly 128 bits. How do you encrypt a 1MB file? This is where block cipher modes come in: they define how to chain multiple blocks together securely.
ECB (Electronic Codebook) is the naive approach: encrypt each block independently with the same key. The problem? Identical plaintext blocks produce identical ciphertext blocks. The famous "ECB penguin" image shows this: you can see the penguin's outline in the encrypted image because large areas of identical color encrypt to identical patterns. ECB is essentially broken; never use it for anything longer than one block.
CBC (Cipher Block Chaining) fixes this by XORing each plaintext block with the previous ciphertext block before encryption. This creates a chain where each block depends on all previous blocks, hiding patterns. However, CBC doesn't detect tampering.
GCM (Galois/Counter Mode) is the modern standard. It uses counter mode (encrypting sequential counters, then XORing with plaintext) combined with a polynomial-based authentication tag. GCM provides both confidentiality and authenticity, can be parallelized, and doesn't require padding. Use GCM unless you have a specific reason not to.
ECB encrypts each block independently. Identical plaintext blocks → identical ciphertext blocks. The famous "ECB Penguin" shows this: encrypt a penguin image with ECB and the shape is still visible!
GCM = Galois/Counter Mode. Combines encryption (CTR mode) with authentication (GMAC). Detects any tampering. Used in TLS 1.3, IPsec, SSH. The modern standard.
from cryptography.hazmat.primitives.ciphers.aead import AESGCM
import os
print("=== Block Cipher Modes ===\n")
print("ECB: Each block independent (INSECURE - patterns leak)")
print("CBC: Chains blocks with XOR (no authentication)")
print("GCM: Counter mode + authentication (RECOMMENDED)\n")
# AES-GCM example
key = AESGCM.generate_key(bit_length=256)
aesgcm = AESGCM(key)
nonce = os.urandom(12) # 96-bit nonce
plaintext = b"Secret message"
ciphertext = aesgcm.encrypt(nonce, plaintext, None)
print(f"Plaintext: {plaintext}")
print(f"Nonce: {nonce.hex()}")
print(f"Ciphertext: {ciphertext.hex()}")
# Decrypt and verify
decrypted = aesgcm.decrypt(nonce, ciphertext, None)
print(f"Decrypted: {decrypted}")
print("\n✓ GCM provides encryption + authentication")
package main
import (
"crypto/aes"
"crypto/cipher"
"crypto/rand"
"fmt"
)
func main() {
fmt.Println("=== Block Cipher Modes ===\n")
fmt.Println("ECB: Patterns leak (INSECURE)")
fmt.Println("CBC: No authentication")
fmt.Println("GCM: Encryption + authentication (RECOMMENDED)\n")
// Generate key and create cipher
key := make([]byte, 32) // AES-256
rand.Read(key)
block, _ := aes.NewCipher(key)
aesgcm, _ := cipher.NewGCM(block)
// Generate nonce
nonce := make([]byte, aesgcm.NonceSize())
rand.Read(nonce)
plaintext := []byte("Secret message")
ciphertext := aesgcm.Seal(nil, nonce, plaintext, nil)
fmt.Printf("Plaintext: %s\n", plaintext)
fmt.Printf("Ciphertext: %x\n", ciphertext)
// Decrypt
decrypted, _ := aesgcm.Open(nil, nonce, ciphertext, nil)
fmt.Printf("Decrypted: %s\n", decrypted)
}
use aes_gcm::{Aes256Gcm, KeyInit, Nonce};
use aes_gcm::aead::Aead;
use rand::RngCore;
fn main() {
println!("=== Block Cipher Modes ===\n");
println!("ECB: Patterns leak (INSECURE)");
println!("GCM: Encryption + authentication (RECOMMENDED)\n");
// Generate random key
let mut key_bytes = [0u8; 32];
rand::thread_rng().fill_bytes(&mut key_bytes);
let cipher = Aes256Gcm::new_from_slice(&key_bytes).unwrap();
// Generate nonce
let mut nonce_bytes = [0u8; 12];
rand::thread_rng().fill_bytes(&mut nonce_bytes);
let nonce = Nonce::from_slice(&nonce_bytes);
let plaintext = b"Secret message";
let ciphertext = cipher.encrypt(nonce, plaintext.as_ref()).unwrap();
println!("Plaintext: {:?}", String::from_utf8_lossy(plaintext));
println!("Ciphertext: {:x?}", &ciphertext);
// Decrypt
let decrypted = cipher.decrypt(nonce, ciphertext.as_ref()).unwrap();
println!("Decrypted: {:?}", String::from_utf8_lossy(&decrypted));
}
🔑 Keys & IVs
Understanding the difference between keys and IVs is critical for using encryption correctly. The key is your secret — if it leaks, all data encrypted with it is compromised. An IV (Initialization Vector) or nonce is not secret, but it must be unique for each encryption operation with the same key.
Why do we need an IV? Without one, encrypting the same message twice with the same key produces identical ciphertext — an attacker would know you sent the same message again. The IV randomizes the encryption so identical plaintexts produce different ciphertexts. Think of it as a "salt" for encryption.
Reusing an IV with the same key is catastrophic. In GCM mode, IV reuse allows attackers to forge authentication tags (pretending to be you) and can even leak the authentication key entirely. In CTR mode, IV reuse lets attackers XOR two ciphertexts together to get the XOR of the plaintexts — often enough to recover both messages.
In practice: generate a random 12-byte (96-bit) IV for each encryption with AES-GCM, and prepend it to the ciphertext. The recipient reads the first 12 bytes as the IV. Since the IV doesn't need to be secret, this is safe and convenient.
WEP (WiFi) reused IVs and was cracked in minutes. GCM with reused IV leaks the authentication key — attackers can forge messages. Always generate a fresh IV!
AES-128: 2¹²⁸ possible keys (secure until ~2030s). AES-256: 2²⁵⁶ keys (quantum-resistant). Both use 128-bit blocks. Key size affects security margin, not block size.
import os
print("=== Key & IV Generation ===\n")
# Generate keys
key_128 = os.urandom(16) # 128 bits
key_256 = os.urandom(32) # 256 bits
print(f"AES-128 key ({len(key_128)} bytes): {key_128.hex()[:32]}...")
print(f"AES-256 key ({len(key_256)} bytes): {key_256.hex()[:32]}...")
# Generate IV/Nonce
iv = os.urandom(12) # 96-bit nonce for GCM
print(f"\nGCM nonce ({len(iv)} bytes): {iv.hex()}")
print("\n=== IV Rules ===")
print("• Must be UNIQUE per encryption (with same key)")
print("• Does NOT need to be secret")
print("• Store alongside ciphertext (prepend it)")
print("• 12 bytes (96 bits) for GCM")
print("\n=== Danger: IV Reuse ===")
print("Same (key, IV) pair used twice?")
print("Attacker gets: M1 ⊕ M2 = C1 ⊕ C2")
print("This leaks information about both messages!")
package main
import (
"crypto/rand"
"fmt"
)
func main() {
fmt.Println("=== Key & IV Generation ===\n")
// Generate keys
key128 := make([]byte, 16) // 128 bits
key256 := make([]byte, 32) // 256 bits
rand.Read(key128)
rand.Read(key256)
fmt.Printf("AES-128 key: %x...\n", key128[:8])
fmt.Printf("AES-256 key: %x...\n", key256[:8])
// Generate nonce
nonce := make([]byte, 12) // 96 bits for GCM
rand.Read(nonce)
fmt.Printf("\nGCM nonce: %x\n", nonce)
fmt.Println("\n=== IV Rules ===")
fmt.Println("• UNIQUE per encryption")
fmt.Println("• NOT secret (store with ciphertext)")
fmt.Println("• 12 bytes for AES-GCM")
}
use rand::RngCore;
fn main() {
println!("=== Key & IV Generation ===\n");
// Generate keys
let mut key_128 = [0u8; 16];
let mut key_256 = [0u8; 32];
rand::thread_rng().fill_bytes(&mut key_128);
rand::thread_rng().fill_bytes(&mut key_256);
println!("AES-128 key: {:x?}...", &key_128[..8]);
println!("AES-256 key: {:x?}...", &key_256[..8]);
// Generate nonce
let mut nonce = [0u8; 12]; // 96 bits for GCM
rand::thread_rng().fill_bytes(&mut nonce);
println!("\nGCM nonce: {:x?}", nonce);
println!("\n=== IV Rules ===");
println!("• UNIQUE per encryption");
println!("• NOT secret");
println!("• 12 bytes for AES-GCM");
}
⚿ Asymmetric Encryption
Asymmetric encryption (also called public-key cryptography) was one of the most important inventions in cryptography. It uses a pair of mathematically linked keys: a public key that you share with everyone, and a private key that you never reveal.
The magic is this: anything encrypted with the public key can only be decrypted with the corresponding private key. So if you want to send me a secret message, you encrypt it with my public key (which I've posted on my website), and even though an attacker can see the public key and the encrypted message, only I can decrypt it because only I have the private key.
This elegantly solves the key distribution problem. With symmetric encryption, we needed a secure channel to share the secret key — but if we had a secure channel, why would we need encryption? Asymmetric encryption lets us establish secure communication over an insecure channel. It's how HTTPS works: your browser encrypts a symmetric key using the server's public key, then both sides use that symmetric key for the actual communication.
The tradeoff is speed: RSA encryption is roughly 1000× slower than AES. That's why real systems use hybrid encryption — asymmetric crypto to exchange a symmetric key, then symmetric crypto for the actual data.
Invented in 1977 by Rivest, Shamir, and Adleman at MIT. Based on the difficulty of factoring large primes. Still used everywhere, though being replaced by elliptic curves.
RSA needs much larger keys than AES. 2048-bit RSA ≈ 112-bit security. NIST recommends 3072+ bits for use beyond 2030. Compare: AES-256 is only 256 bits!
Before 1976, sharing encrypted messages required meeting in person to exchange keys. Diffie-Hellman and RSA solved the "key distribution problem" — one of crypto's greatest breakthroughs.
TLS (HTTPS) uses RSA/ECDH to exchange a symmetric key, then AES for the actual data. Best of both worlds: RSA's key exchange + AES's speed.
🔢 RSA Math
RSA's security rests on a simple asymmetry: multiplying two large prime numbers is easy, but factoring the result back into those primes is extraordinarily hard. A computer can multiply two 1000-digit primes in milliseconds, but factoring the result would take longer than the age of the universe.
Here's how RSA works mathematically. You pick two large random primes, p and q, and multiply them to get n = p × q. You publish n (part of the public key) but keep p and q secret. The magic is that certain mathematical operations on n can only be reversed if you know p and q — creating a "trapdoor" function.
Encryption is essentially: ciphertext = messagee mod n, where e is the public exponent. Decryption is: message = ciphertextd mod n, where d is the private exponent. The relationship between e and d depends on knowing p and q — without them, computing d from e and n is as hard as factoring n.
Modern RSA uses 2048-bit or 4096-bit keys. Factoring a 2048-bit number is estimated to require about 2¹¹² operations — well beyond current computational capabilities. However, quantum computers running Shor's algorithm could factor in polynomial time, which is why post-quantum cryptography is an active research area.
RSA-2048 uses two 1024-bit primes. These are ~300 digits each! Finding them uses probabilistic primality tests (Miller-Rabin). The primes must be random and kept secret forever.
φ(n) = (p-1)(q-1) counts integers less than n that are coprime to n. This is the "secret" that makes RSA work — easy to compute with p,q but hard without them.
Euler's theorem: m^(e×d) ≡ m (mod n) when e×d ≡ 1 (mod φ(n)). So encrypt then decrypt recovers the original. Finding d from e requires φ(n), which requires factoring n.
# RSA key generation (simplified with small primes)
print("=== RSA Key Generation ===\n")
# Step 1: Choose two primes
p, q = 61, 53
print(f"Step 1: Primes p={p}, q={q}")
# Step 2: Compute n = p × q
n = p * q
print(f"Step 2: n = p×q = {n}")
# Step 3: Compute φ(n) = (p-1)(q-1)
phi_n = (p - 1) * (q - 1)
print(f"Step 3: φ(n) = {phi_n}")
# Step 4: Choose e (public exponent)
e = 17
print(f"Step 4: e = {e}")
# Step 5: Compute d = e⁻¹ mod φ(n)
d = pow(e, -1, phi_n) # Python 3.8+
print(f"Step 5: d = {d}")
print(f"\nPublic key: (n={n}, e={e})")
print(f"Private key: (n={n}, d={d})")
# Demo encryption
m = 42
c = pow(m, e, n) # c = m^e mod n
m2 = pow(c, d, n) # m = c^d mod n
print(f"\nEncrypt {m}: {c}")
print(f"Decrypt {c}: {m2}")
package main
import (
"fmt"
"math/big"
)
func main() {
fmt.Println("=== RSA Key Generation ===\n")
p := big.NewInt(61)
q := big.NewInt(53)
// n = p × q
n := new(big.Int).Mul(p, q)
fmt.Printf("n = p×q = %d\n", n)
// φ(n) = (p-1)(q-1)
pMinus1 := new(big.Int).Sub(p, big.NewInt(1))
qMinus1 := new(big.Int).Sub(q, big.NewInt(1))
phi := new(big.Int).Mul(pMinus1, qMinus1)
fmt.Printf("φ(n) = %d\n", phi)
e := big.NewInt(17)
d := new(big.Int).ModInverse(e, phi)
fmt.Printf("e = %d, d = %d\n", e, d)
// Encrypt/decrypt
m := big.NewInt(42)
c := new(big.Int).Exp(m, e, n) // c = m^e mod n
m2 := new(big.Int).Exp(c, d, n) // m = c^d mod n
fmt.Printf("\nEncrypt %d → %d → %d\n", m, c, m2)
}
use num_bigint::BigUint;
use num_traits::One;
fn mod_inverse(a: &BigUint, m: &BigUint) -> BigUint {
a.modpow(&(m - 2u32), m) // Only works when m is prime or coprime
}
fn main() {
println!("=== RSA Key Generation ===\n");
let p = BigUint::from(61u32);
let q = BigUint::from(53u32);
// n = p × q
let n = &p * &q;
println!("n = p×q = {}", n);
// φ(n) = (p-1)(q-1)
let phi: BigUint = (&p - 1u32) * (&q - 1u32);
println!("φ(n) = {}", phi);
let e = BigUint::from(17u32);
// d = e^(-1) mod φ(n) using extended Euclidean
let d = BigUint::from(2753u32); // Precomputed for this example
println!("e = {}, d = {}", e, d);
// Encrypt/decrypt
let m = BigUint::from(42u32);
let c = m.modpow(&e, &n);
let m2 = c.modpow(&d, &n);
println!("\nEncrypt {} → {} → {}", m, c, m2);
}
🤝 Key Exchange
Key exchange solves a seemingly impossible problem: how can two people who have never met establish a shared secret while an eavesdropper watches their entire conversation? The answer is Diffie-Hellman, one of the most elegant algorithms in cryptography.
The intuition is like mixing paint. Alice picks a secret color and mixes it with a public color they've agreed on. Bob does the same with his secret color. They exchange their mixed colors publicly. Now Alice adds her secret to Bob's mix, and Bob adds his secret to Alice's mix — and remarkably, they both end up with the same final color, which an eavesdropper can't compute because they don't know either secret.
Mathematically, this uses modular exponentiation. In a group with generator g and prime modulus p: Alice computes A = ga mod p (her public value), Bob computes B = gb mod p (his public value). They exchange A and B. Alice computes Ba = gba mod p, Bob computes Ab = gab mod p — and since ab = ba, they get the same shared secret.
Modern systems use ECDH (Elliptic Curve Diffie-Hellman), which provides the same security with much smaller key sizes. A 256-bit elliptic curve provides roughly the same security as 3072-bit traditional DH. Every HTTPS connection you make likely uses ECDH.
Published by Whitfield Diffie and Martin Hellman. Later revealed: GCHQ's James Ellis and Clifford Cocks discovered it in 1969 but kept it classified. The first public-key protocol!
Modern HTTPS uses Elliptic Curve Diffie-Hellman (ECDH). Each connection generates fresh keys (forward secrecy). Even if the server's private key leaks, past sessions stay protected.
from cryptography.hazmat.primitives.asymmetric import x25519
# Generate key pairs
alice_private = x25519.X25519PrivateKey.generate()
alice_public = alice_private.public_key()
bob_private = x25519.X25519PrivateKey.generate()
bob_public = bob_private.public_key()
# Exchange public keys and derive shared secret
alice_shared = alice_private.exchange(bob_public)
bob_shared = bob_private.exchange(alice_public)
print("=== X25519 Key Exchange ===\n")
print(f"Alice public: {alice_public.public_bytes_raw().hex()[:32]}...")
print(f"Bob public: {bob_public.public_bytes_raw().hex()[:32]}...")
print(f"\nAlice's shared secret: {alice_shared.hex()[:32]}...")
print(f"Bob's shared secret: {bob_shared.hex()[:32]}...")
print(f"\nSecrets match: {alice_shared == bob_shared}")
package main
import (
"crypto/rand"
"fmt"
"golang.org/x/crypto/curve25519"
)
func main() {
// Generate Alice's key pair
var alicePrivate, alicePublic [32]byte
rand.Read(alicePrivate[:])
curve25519.ScalarBaseMult(&alicePublic, &alicePrivate)
// Generate Bob's key pair
var bobPrivate, bobPublic [32]byte
rand.Read(bobPrivate[:])
curve25519.ScalarBaseMult(&bobPublic, &bobPrivate)
// Derive shared secrets
var aliceShared, bobShared [32]byte
curve25519.ScalarMult(&aliceShared, &alicePrivate, &bobPublic)
curve25519.ScalarMult(&bobShared, &bobPrivate, &alicePublic)
fmt.Println("=== X25519 Key Exchange ===\n")
fmt.Printf("Alice shared: %x...\n", aliceShared[:16])
fmt.Printf("Bob shared: %x...\n", bobShared[:16])
fmt.Printf("Match: %v\n", aliceShared == bobShared)
}
use x25519_dalek::{EphemeralSecret, PublicKey};
use rand::rngs::OsRng;
fn main() {
// Generate Alice's key pair
let alice_secret = EphemeralSecret::random_from_rng(OsRng);
let alice_public = PublicKey::from(&alice_secret);
// Generate Bob's key pair
let bob_secret = EphemeralSecret::random_from_rng(OsRng);
let bob_public = PublicKey::from(&bob_secret);
// Derive shared secrets
let alice_shared = alice_secret.diffie_hellman(&bob_public);
let bob_shared = bob_secret.diffie_hellman(&alice_public);
println!("=== X25519 Key Exchange ===\n");
println!("Alice shared: {:x?}...", &alice_shared.as_bytes()[..16]);
println!("Bob shared: {:x?}...", &bob_shared.as_bytes()[..16]);
println!("Match: {}", alice_shared.as_bytes() == bob_shared.as_bytes());
}
✓ Digital Signatures
Digital signatures are asymmetric cryptography in reverse. With encryption, anyone can encrypt (using the public key) but only one person can decrypt (using the private key). With signatures, only one person can sign (using the private key) but anyone can verify (using the public key).
This provides two powerful guarantees. Authentication: the signature proves the message came from someone who possesses the private key, because only they could have created that specific signature. Integrity: any modification to the message invalidates the signature, because signatures are computed over the exact bytes of the message.
Unlike a handwritten signature (which looks the same on every document), a digital signature is different for every message. It's computed from both the message content and the private key, so it's impossible to "lift" a signature from one document and paste it onto another.
Digital signatures enable non-repudiation: if I sign a contract, I can't later claim I didn't sign it (assuming I kept my private key secure). They're used everywhere — HTTPS certificates, software updates, email (S/MIME, PGP), JWTs, legal documents, and every cryptocurrency transaction.
Encryption hides data. Signatures prove authorship. You sign with your PRIVATE key (only you can sign), others verify with your PUBLIC key (anyone can verify).
Unlike passwords or symmetric keys, signatures prove a specific person signed something. Used in legal contracts, code signing, and financial transactions. You can't deny signing it!
RSA-PSS adds randomness to each signature, so signing the same message twice produces different signatures. More secure than older PKCS#1 v1.5 signatures.
🔍 Verification Flow
Signature verification is the counterpart to signing: given a message, a signature, and a public key, determine whether the signature is valid. A valid signature proves the message was signed by the corresponding private key and hasn't been modified since.
The process never needs the private key — that's the whole point. Anyone with the public key can verify, but only the private key holder can create valid signatures. This is what enables scenarios like software updates: the developer signs with their private key, and millions of users verify with the published public key.
Verification is also fast: typically you hash the message (fast) and perform one modular exponentiation or elliptic curve operation. This is important because signatures often need to be verified many times (every user downloading the software) while only being created once.
RSA can only sign data smaller than its key size. We hash the message to a fixed size (256 bits), then sign the hash. The signature binds to the hash, which binds to the message.
Sign: signature = hash^d mod n (using private key d). Verify: hash' = signature^e mod n (using public key e). If hash' == hash(message), signature is valid.
from cryptography.hazmat.primitives.asymmetric import rsa, padding
from cryptography.hazmat.primitives import hashes
# Generate key pair
private_key = rsa.generate_private_key(public_exponent=65537, key_size=2048)
public_key = private_key.public_key()
# Sign a message
message = b"Hello, World!"
signature = private_key.sign(
message,
padding.PSS(mgf=padding.MGF1(hashes.SHA256()), salt_length=padding.PSS.MAX_LENGTH),
hashes.SHA256()
)
print(f"Message: {message}")
print(f"Signature: {signature.hex()[:40]}...")
# Verify (anyone can do this with public key)
try:
public_key.verify(signature, message,
padding.PSS(mgf=padding.MGF1(hashes.SHA256()), salt_length=padding.PSS.MAX_LENGTH),
hashes.SHA256())
print("\n✓ Signature valid")
except:
print("\n✗ Signature invalid")
package main
import (
"crypto/rand"
"crypto/rsa"
"crypto/sha256"
"fmt"
)
func main() {
// Generate key pair
privateKey, _ := rsa.GenerateKey(rand.Reader, 2048)
publicKey := &privateKey.PublicKey
message := []byte("Hello, World!")
hash := sha256.Sum256(message)
// Sign with private key
signature, _ := rsa.SignPKCS1v15(rand.Reader, privateKey,
crypto.SHA256, hash[:])
fmt.Printf("Message: %s\n", message)
fmt.Printf("Signature: %x...\n", signature[:20])
// Verify with public key
err := rsa.VerifyPKCS1v15(publicKey, crypto.SHA256, hash[:], signature)
if err == nil {
fmt.Println("\n✓ Signature valid")
} else {
fmt.Println("\n✗ Signature invalid")
}
}
use rsa::{RsaPrivateKey, RsaPublicKey, pkcs1v15::{SigningKey, VerifyingKey}};
use rsa::signature::{Signer, Verifier};
use sha2::Sha256;
fn main() {
// Generate key pair
let mut rng = rand::thread_rng();
let private_key = RsaPrivateKey::new(&mut rng, 2048).unwrap();
let public_key = RsaPublicKey::from(&private_key);
let signing_key = SigningKey::::new(private_key);
let verifying_key = VerifyingKey::::new(public_key);
let message = b"Hello, World!";
// Sign with private key
let signature = signing_key.sign(message);
println!("Message: {:?}", String::from_utf8_lossy(message));
// Verify with public key
match verifying_key.verify(message, &signature) {
Ok(_) => println!("\n✓ Signature valid"),
Err(_) => println!("\n✗ Signature invalid"),
}
}
📜 Certificates & PKI
Public-key cryptography has a trust problem: if I give you a public key and claim it belongs to "Bank of America," how do you know I'm not an attacker? Digital certificates solve this by having a trusted third party vouch for the association between a public key and an identity.
A certificate is essentially a statement: "I, Certificate Authority X, certify that this public key belongs to bank.com" — signed with the CA's private key. Your browser comes pre-installed with a list of trusted root CAs (about 100-150 organizations). When you visit https://bank.com, the server presents its certificate, your browser verifies the CA's signature, and if the signature is valid and the CA is trusted, you can trust the public key.
In practice, there's usually a chain of trust: the root CA signs an intermediate CA's certificate, the intermediate signs the website's certificate. This limits exposure of the root CA's private key. Your browser follows the chain back to a trusted root, verifying each signature along the way.
The certificate also includes metadata: validity dates (certificates expire), the domain name(s) it's valid for, and the allowed usages (e.g., server authentication). Browsers check all of this — an expired certificate or a certificate for the wrong domain triggers a security warning.
~150 root CAs are pre-installed in your browser/OS. They verify domain ownership before signing certificates. Let's Encrypt issues free certificates automatically via ACME protocol.
Root CA → Intermediate CA → Your Cert. Roots are kept offline (ultra-secure). Intermediates do daily signing. If an intermediate is compromised, only that chain is revoked.
from cryptography import x509
from cryptography.x509.oid import NameOID
import ssl
import socket
# Fetch certificate from a real website
hostname = "google.com"
ctx = ssl.create_default_context()
with ctx.wrap_socket(socket.socket(), server_hostname=hostname) as s:
s.connect((hostname, 443))
cert_der = s.getpeercert(binary_form=True)
cert = x509.load_der_x509_certificate(cert_der)
print(f"=== Certificate for {hostname} ===\n")
print(f"Subject: {cert.subject.get_attributes_for_oid(NameOID.COMMON_NAME)[0].value}")
print(f"Issuer: {cert.issuer.get_attributes_for_oid(NameOID.ORGANIZATION_NAME)[0].value}")
print(f"Valid from: {cert.not_valid_before_utc}")
print(f"Valid until: {cert.not_valid_after_utc}")
print(f"Serial: {cert.serial_number}")
print(f"Signature algorithm: {cert.signature_algorithm_oid._name}")
package main
import (
"crypto/tls"
"fmt"
)
func main() {
hostname := "google.com:443"
conn, _ := tls.Dial("tcp", hostname, nil)
defer conn.Close()
cert := conn.ConnectionState().PeerCertificates[0]
fmt.Println("=== Certificate for google.com ===\n")
fmt.Printf("Subject: %s\n", cert.Subject.CommonName)
fmt.Printf("Issuer: %s\n", cert.Issuer.Organization[0])
fmt.Printf("Valid from: %s\n", cert.NotBefore)
fmt.Printf("Valid until: %s\n", cert.NotAfter)
fmt.Printf("Serial: %d\n", cert.SerialNumber)
fmt.Printf("Signature algorithm: %s\n", cert.SignatureAlgorithm)
}
// Using rustls and x509-parser crates
use x509_parser::prelude::*;
fn main() {
// In practice, you'd fetch cert bytes from TLS connection
let cert_bytes: &[u8] = include_bytes!("cert.der");
let (_, cert) = X509Certificate::from_der(cert_bytes).unwrap();
println!("=== X.509 Certificate ===\n");
println!("Subject: {:?}", cert.subject());
println!("Issuer: {:?}", cert.issuer());
println!("Valid from: {:?}", cert.validity().not_before);
println!("Valid until: {:?}", cert.validity().not_after);
println!("Serial: {:?}", cert.serial);
println!("Signature algo: {:?}", cert.signature_algorithm.algorithm);
}
⊕ HMAC
HMAC (Hash-based Message Authentication Code) combines a secret key with a hash function. Unlike plain hashes, HMACs prove both integrity and authenticity — only someone with the secret key can create or verify the code. Used extensively in API authentication, session tokens, and secure cookies. The key difference from signatures: HMACs use symmetric keys (both parties share the secret), while signatures use asymmetric keys.
Never use SHA256(secret + message) — vulnerable to length extension attacks! HMAC uses a special construction that's provably secure.
Stripe, GitHub, Twilio all sign webhooks with HMAC. Your server shares a secret with them. When you receive a webhook, verify the signature before trusting it.
JSON Web Tokens are often signed with HMAC-SHA256 (HS256). The server keeps the secret and can verify tokens it issued. Fast and simple for single-server setups.
🔐 HMAC vs Plain Hash
Why not just concatenate the key and message, then hash? Because of length extension attacks! With SHA-256(key || message), an attacker who knows the hash can compute SHA-256(key || message || attacker_data) without knowing the key.
SHA-256's Merkle-Damgård construction lets attackers "resume" hashing from a known hash. Given H(secret || msg), they can compute H(secret || msg || padding || evil) without the secret!
HMAC = H(K ⊕ opad || H(K ⊕ ipad || message)). Two nested hashes with XOR'd keys. This prevents length extension and proves knowledge of the key.
import hmac
import hashlib
key = b"supersecret"
message = b"Hello, World!"
# WRONG: hash(key + message) — vulnerable to length extension!
bad_mac = hashlib.sha256(key + message).hexdigest()
print("=== Don't do this ===")
print(f"SHA-256(key + msg): {bad_mac[:32]}...")
print("⚠️ Vulnerable to length extension attacks!\n")
# RIGHT: Use HMAC
good_mac = hmac.new(key, message, hashlib.sha256).hexdigest()
print("=== Do this ===")
print(f"HMAC-SHA256: {good_mac[:32]}...")
print("✓ Safe from length extension attacks")
print("\n=== Why HMAC works ===")
print("HMAC(K, M) = H((K⊕opad) || H((K⊕ipad) || M))")
print("Nested hashing prevents length extension")
package main
import (
"crypto/hmac"
"crypto/sha256"
"fmt"
)
func main() {
key := []byte("supersecret")
message := []byte("Hello, World!")
// WRONG: hash(key + message)
h := sha256.New()
h.Write(key)
h.Write(message)
badMac := h.Sum(nil)
fmt.Printf("SHA-256(key+msg): %x...\n", badMac[:16])
fmt.Println("⚠️ Vulnerable to length extension!\n")
// RIGHT: Use HMAC
mac := hmac.New(sha256.New, key)
mac.Write(message)
goodMac := mac.Sum(nil)
fmt.Printf("HMAC-SHA256: %x...\n", goodMac[:16])
fmt.Println("✓ Safe from length extension")
}
use hmac::{Hmac, Mac};
use sha2::Sha256;
type HmacSha256 = Hmac;
fn main() {
let key = b"supersecret";
let message = b"Hello, World!";
// WRONG: Would be hash(key + message)
// Don't do this — vulnerable to length extension!
// RIGHT: Use HMAC
let mut mac = HmacSha256::new_from_slice(key).unwrap();
mac.update(message);
let result = mac.finalize();
println!("HMAC-SHA256: {:x?}...", &result.into_bytes()[..16]);
println!("✓ Safe from length extension attacks");
println!("\n=== Why HMAC works ===");
println!("Nested structure: H((K⊕opad) || H((K⊕ipad) || M))");
}
⏱️ Timing Attacks
When comparing two strings, naive code stops at the first mismatch. An attacker can measure response times: if the first byte matches, it takes slightly longer. By trying all values for each position, they can extract the secret byte-by-byte.
Google's crypto library had timing-vulnerable HMAC verification. Researchers could extract a 32-byte MAC in ~20,000 requests by measuring microsecond differences.
XOR all bytes and OR the results. Check if final value is 0. Same operations regardless of where mismatch occurs. crypto.subtle.verify() does this automatically.
import hmac
import secrets
secret = b"mysecretkey"
user_input = b"mysecretkey"
# WRONG: Early exit comparison
def bad_compare(a, b):
if len(a) != len(b):
return False
for x, y in zip(a, b):
if x != y:
return False # Exits early — timing leak!
return True
# RIGHT: Constant-time comparison
def good_compare(a, b):
return hmac.compare_digest(a, b) # Always same time
print("=== Timing Attack Prevention ===\n")
print(f"bad_compare: {bad_compare(secret, user_input)}")
print("⚠️ Vulnerable to timing attack\n")
print(f"hmac.compare_digest: {good_compare(secret, user_input)}")
print("✓ Constant time — safe from timing attacks")
print("\n=== Why this matters ===")
print("Attackers measure microsecond differences")
print("to extract secrets byte-by-byte")
package main
import (
"crypto/subtle"
"fmt"
)
func main() {
secret := []byte("mysecretkey")
userInput := []byte("mysecretkey")
// WRONG: bytes.Equal exits early
// badResult := bytes.Equal(secret, userInput)
// RIGHT: constant-time comparison
result := subtle.ConstantTimeCompare(secret, userInput)
fmt.Println("=== Timing Attack Prevention ===\n")
fmt.Printf("subtle.ConstantTimeCompare: %v\n", result == 1)
fmt.Println("✓ Always takes same time")
fmt.Println("\n=== The crypto/subtle package ===")
fmt.Println("• ConstantTimeCompare — safe string comparison")
fmt.Println("• ConstantTimeSelect — branchless selection")
fmt.Println("• ConstantTimeCopy — conditional copy")
}
use subtle::ConstantTimeEq;
fn main() {
let secret = b"mysecretkey";
let user_input = b"mysecretkey";
// WRONG: == operator exits early on mismatch
// let bad = secret == user_input;
// RIGHT: constant-time comparison with subtle crate
let result = secret.ct_eq(user_input);
println!("=== Timing Attack Prevention ===\n");
println!("ct_eq result: {:?}", bool::from(result));
println!("✓ Always takes same time");
println!("\n=== The subtle crate ===");
println!("• ct_eq — constant-time equality");
println!("• conditional_select — branchless choice");
println!("• Returns Choice type, not bool (prevents accidental use)");
}
◈ Key Derivation
Passwords make poor encryption keys — they're short and predictable. Key derivation functions like PBKDF2 stretch a password into a strong cryptographic key. The iteration count deliberately slows down the process, making brute-force attacks impractical. A unique salt prevents precomputed rainbow table attacks. Modern alternatives include Argon2 and scrypt, which also require significant memory.
Introduced in 2000 (RFC 2898). Still widely used, but newer alternatives like Argon2 (2015 winner of Password Hashing Competition) are more resistant to GPU attacks.
Without salt, identical passwords produce identical hashes — attackers precompute "rainbow tables" of common passwords. A random salt makes each hash unique, forcing per-password attacks.
OWASP recommends 600,000+ for PBKDF2-SHA256 (2023). The goal: make each guess take ~100ms. Double iterations every 2 years as hardware improves.
6.5 million passwords leaked — stored as unsalted SHA-1. Easily cracked. Modern sites use bcrypt, scrypt, or Argon2 with high work factors. Never store plain hashes!
Created in 1999, still widely used. Has a built-in salt and adaptive cost factor. Why not in Web Crypto? It's designed for passwords only, not key derivation. Use bcrypt.js in Node or the server-side.
🧂 Salt & Iterations
A salt is random data added to a password before hashing. It prevents attackers from using precomputed "rainbow tables." Iterations (or work factor) deliberately slow down hashing — making brute-force attacks take years instead of seconds.
Precomputed tables mapping common passwords to their hashes. "password123" → hash. With a unique salt per user, attackers must compute each hash from scratch.
GPUs can compute billions of plain SHA-256 hashes/second. With 100,000 iterations, that drops to ~10,000/second. A 10-character password would take centuries to crack.
import hashlib
import os
password = b"hunter2"
salt = os.urandom(16) # Random 128-bit salt
iterations = 600_000 # OWASP 2023 recommendation
# PBKDF2 with salt and iterations
key = hashlib.pbkdf2_hmac('sha256', password, salt, iterations)
print("=== PBKDF2 with Salt & Iterations ===\n")
print(f"Password: {password.decode()}")
print(f"Salt: {salt.hex()}")
print(f"Iterations: {iterations:,}")
print(f"Derived key: {key.hex()[:32]}...")
print("\n=== Why this matters ===")
print("• Salt prevents rainbow tables")
print("• Iterations slow down brute force")
print("• 600k iterations ≈ 0.5-1 second per attempt")
package main
import (
"crypto/rand"
"crypto/sha256"
"fmt"
"golang.org/x/crypto/pbkdf2"
)
func main() {
password := []byte("hunter2")
salt := make([]byte, 16)
rand.Read(salt)
iterations := 600_000
key := pbkdf2.Key(password, salt, iterations, 32, sha256.New)
fmt.Println("=== PBKDF2 with Salt & Iterations ===\n")
fmt.Printf("Password: %s\n", password)
fmt.Printf("Salt: %x\n", salt)
fmt.Printf("Iterations: %d\n", iterations)
fmt.Printf("Key: %x...\n", key[:16])
}
use pbkdf2::pbkdf2_hmac;
use sha2::Sha256;
use rand::RngCore;
fn main() {
let password = b"hunter2";
let mut salt = [0u8; 16];
rand::thread_rng().fill_bytes(&mut salt);
let iterations = 600_000;
let mut key = [0u8; 32];
pbkdf2_hmac::(password, &salt, iterations, &mut key);
println!("=== PBKDF2 with Salt & Iterations ===\n");
println!("Password: {}", String::from_utf8_lossy(password));
println!("Salt: {:x?}", salt);
println!("Iterations: {}", iterations);
println!("Key: {:x?}...", &key[..16]);
}
💾 Memory-Hard KDFs
PBKDF2 is CPU-bound — attackers can use GPUs (thousands of parallel cores) to crack passwords faster. Memory-hard functions like bcrypt, scrypt, and Argon2 require significant RAM, which is expensive on GPUs and ASICs.
Based on the Blowfish cipher. Uses 4KB of RAM — small but enough to slow down early GPUs. Cost factor doubles work each increment. Cost 12 ≈ 250ms on modern hardware.
Winner of the Password Hashing Competition. Configurable memory (1MB-1GB), parallelism, and time. Argon2id is recommended: resistant to both GPU and side-channel attacks.
import bcrypt
# pip install argon2-cffi
from argon2 import PasswordHasher
password = b"hunter2"
# bcrypt — classic memory-hard KDF
bcrypt_hash = bcrypt.hashpw(password, bcrypt.gensalt(rounds=12))
print("=== bcrypt ===")
print(f"Hash: {bcrypt_hash.decode()}")
print("✓ Memory-hard, GPU-resistant\n")
# Argon2id — modern winner (2015 PHC)
ph = PasswordHasher(time_cost=3, memory_cost=65536, parallelism=4)
argon2_hash = ph.hash(password.decode())
print("=== Argon2id ===")
print(f"Hash: {argon2_hash[:60]}...")
print("✓ Best choice for new applications")
print(" - time_cost: iterations")
print(" - memory_cost: KB of RAM (65MB here)")
print(" - parallelism: threads")
package main
import (
"fmt"
"golang.org/x/crypto/bcrypt"
"golang.org/x/crypto/argon2"
"crypto/rand"
)
func main() {
password := []byte("hunter2")
// bcrypt
bcryptHash, _ := bcrypt.GenerateFromPassword(password, 12)
fmt.Println("=== bcrypt ===")
fmt.Printf("Hash: %s\n\n", bcryptHash)
// Argon2id
salt := make([]byte, 16)
rand.Read(salt)
argon2Hash := argon2.IDKey(password, salt, 3, 64*1024, 4, 32)
fmt.Println("=== Argon2id ===")
fmt.Printf("Hash: %x...\n", argon2Hash[:16])
fmt.Println("Parameters: time=3, memory=64MB, threads=4")
}
use argon2::{Argon2, password_hash::{PasswordHasher, SaltString, rand_core::OsRng}};
fn main() {
let password = b"hunter2";
// Argon2id with recommended settings
let salt = SaltString::generate(&mut OsRng);
let argon2 = Argon2::default(); // Uses Argon2id
let hash = argon2.hash_password(password, &salt).unwrap();
println!("=== Argon2id ===");
println!("Hash: {}...", &hash.to_string()[..60]);
println!("\n✓ Memory-hard, GPU-resistant");
println!(" Default: 19MB memory, 2 iterations, 1 thread");
}
⚄ Secure Random
Randomness is the foundation of all cryptography. Keys, IVs, salts, and nonces must be unpredictable. Standard random functions like Math.random() are pseudo-random — attackers can predict future values from past ones. Cryptographic random generators (CSPRNGs) use entropy from hardware sources (mouse movements, disk timing, CPU noise) to produce truly unpredictable values.
Math.random() is a PRNG — fast but predictable. crypto.getRandomValues() is a CSPRNG — cryptographically secure. Never use Math.random() for security!
Your OS collects "entropy" from unpredictable sources: mouse movements, keyboard timing, disk I/O, network jitter, hardware noise. Intel's RDRAND instruction provides hardware randomness.
UUIDv4 uses random bytes (not MAC address like v1). 2^122 ≈ 5×10³⁶ possibilities. At 1 billion UUIDs/second, a collision takes ~100 trillion years.
Sony used the same random number for every ECDSA signature. Hackers extracted the private key and could sign any software. This is why randomness matters!
🎲 Entropy Sources
Entropy is randomness collected from physical sources. Your operating system continuously gathers entropy from unpredictable events: keyboard timing, mouse movements, disk I/O latency, network packet timing, and hardware noise. This "entropy pool" seeds the CSPRNG.
Linux maintains an entropy pool fed by hardware events. /dev/random blocks when entropy is low; /dev/urandom never blocks (uses CSPRNG). Modern kernels prefer urandom.
Modern Intel/AMD CPUs have a hardware random number generator. The RDRAND instruction provides 64 bits of hardware randomness per call. Some distrust it (NSA backdoor concerns), so OSes mix it with other sources.
import os
import secrets
print("=== Entropy Sources ===\n")
# os.urandom — reads from /dev/urandom (Linux) or CryptGenRandom (Windows)
entropy = os.urandom(32)
print(f"os.urandom(32): {entropy.hex()[:32]}...")
print("→ Uses OS entropy pool (keyboard, mouse, disk I/O, etc.)\n")
# secrets module — Python 3.6+ recommended for crypto
token = secrets.token_hex(16)
print(f"secrets.token_hex(16): {token}")
print("→ Wrapper around os.urandom, recommended API\n")
# Check available entropy (Linux only)
try:
with open('/proc/sys/kernel/random/entropy_avail', 'r') as f:
available = f.read().strip()
print(f"Entropy available: {available} bits")
except:
print("Entropy check: N/A (not Linux)")
package main
import (
"crypto/rand"
"fmt"
"io"
)
func main() {
fmt.Println("=== Entropy Sources ===\n")
// crypto/rand.Reader — reads from /dev/urandom
entropy := make([]byte, 32)
io.ReadFull(rand.Reader, entropy)
fmt.Printf("crypto/rand: %x...\n", entropy[:16])
fmt.Println("→ Uses OS entropy pool\n")
// Generate random int
var n [8]byte
rand.Read(n[:])
fmt.Printf("Random bytes: %x\n", n)
fmt.Println("\n=== Go's crypto/rand ===")
fmt.Println("• Always uses OS CSPRNG")
fmt.Println("• Blocks if entropy is low (rare)")
fmt.Println("• Safe for keys, IVs, tokens")
}
use rand::{RngCore, rngs::OsRng};
use getrandom::getrandom;
fn main() {
println!("=== Entropy Sources ===\n");
// OsRng — uses OS entropy directly
let mut entropy = [0u8; 32];
OsRng.fill_bytes(&mut entropy);
println!("OsRng: {:x?}...", &entropy[..16]);
println!("→ Uses OS entropy pool\n");
// getrandom — lower-level OS interface
let mut bytes = [0u8; 16];
getrandom(&mut bytes).unwrap();
println!("getrandom: {:x?}", bytes);
println!("\n=== Rust's rand ecosystem ===");
println!("• OsRng: OS-level CSPRNG");
println!("• getrandom: System calls directly");
println!("• thread_rng: Fast, seeded from OsRng");
}
🔀 PRNG vs CSPRNG
A PRNG (Pseudo-Random Number Generator) produces numbers that look random but are entirely determined by an initial seed. A CSPRNG (Cryptographically Secure PRNG) is designed so that even knowing previous outputs, you cannot predict future ones.
Many PRNGs use: next = (a * current + c) mod m. Fast but predictable. If you know the constants and one output, you know ALL future outputs.
In 1999, researchers broke ASF Software's online poker by reverse-engineering their PRNG. They could predict the shuffle from observing dealt cards. $millions were at stake.
import random
import secrets
print("=== PRNG (random module) — NOT for crypto ===\n")
random.seed(12345) # Predictable!
prng_nums = [random.randint(0, 100) for _ in range(5)]
print(f"random.seed(12345): {prng_nums}")
random.seed(12345) # Same seed
prng_nums2 = [random.randint(0, 100) for _ in range(5)]
print(f"same seed again: {prng_nums2}")
print("⚠️ Same seed = same sequence!\n")
print("=== CSPRNG (secrets module) — Use for crypto ===\n")
csprng_nums = [secrets.randbelow(100) for _ in range(5)]
print(f"secrets.randbelow: {csprng_nums}")
csprng_nums2 = [secrets.randbelow(100) for _ in range(5)]
print(f"secrets again: {csprng_nums2}")
print("✓ Unpredictable every time!")
print("\n=== Quick guide ===")
print("• random: games, simulations, shuffling")
print("• secrets: tokens, keys, passwords")
package main
import (
"crypto/rand"
"fmt"
"math/big"
mrand "math/rand"
)
func main() {
fmt.Println("=== PRNG (math/rand) — NOT for crypto ===\n")
mrand.Seed(12345)
nums := make([]int64, 5)
for i := range nums { nums[i] = mrand.Int63n(100) }
fmt.Printf("seed(12345): %v\n", nums)
mrand.Seed(12345)
for i := range nums { nums[i] = mrand.Int63n(100) }
fmt.Printf("same seed: %v\n", nums)
fmt.Println("⚠️ Same seed = same sequence!\n")
fmt.Println("=== CSPRNG (crypto/rand) — Use for crypto ===\n")
for i := 0; i < 5; i++ {
n, _ := rand.Int(rand.Reader, big.NewInt(100))
fmt.Printf("crypto/rand: %d\n", n)
}
fmt.Println("✓ Unpredictable!")
}
use rand::{Rng, SeedableRng, rngs::{StdRng, OsRng}};
fn main() {
println!("=== PRNG (seeded) — NOT for crypto ===\n");
let mut prng = StdRng::seed_from_u64(12345);
let nums: Vec = (0..5).map(|_| prng.gen_range(0..100)).collect();
println!("seed(12345): {:?}", nums);
let mut prng2 = StdRng::seed_from_u64(12345);
let nums2: Vec = (0..5).map(|_| prng2.gen_range(0..100)).collect();
println!("same seed: {:?}", nums2);
println!("⚠️ Same seed = same sequence!\n");
println!("=== CSPRNG (OsRng) — Use for crypto ===\n");
let mut csprng = OsRng;
let secure: Vec = (0..5).map(|_| csprng.gen_range(0..100)).collect();
println!("OsRng: {:?}", secure);
println!("✓ Unpredictable!");
}
crypto.getRandomValues() for anything security-related. Use Math.random() only for games, animations, or shuffling playlists.